
Phần lớn mọi người nghĩ RAG chỉ đơn giản là “Vector DB + LLM”
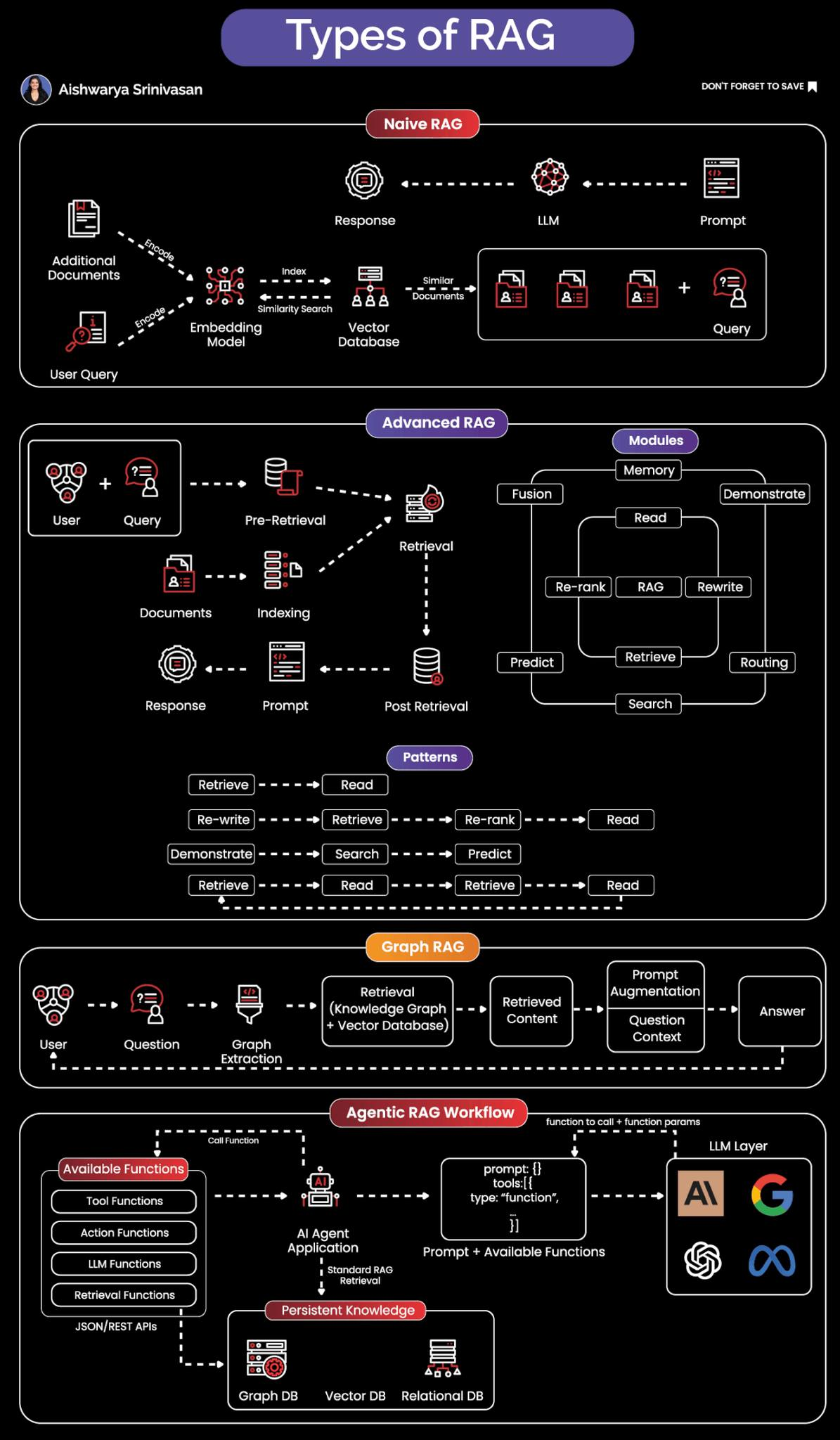
Phần lớn mọi người nghĩ RAG chỉ đơn giản là “Vector DB + LLM”.
Nhưng khi triển khai ở quy mô lớn cho các bài toán thực tế, Naive RAG nhanh chóng bộc lộ hạn chế.
Dưới đây là 4 cấp độ RAG và cách chúng tiến hóa:
Dưới đây là 4 cấp độ RAG và cách chúng tiến hóa:
-
Embed câu hỏi → lấy top-k chunk → nhồi vào prompt.
-
Tốt cho Q&A đơn giản, nhưng yếu khi cần suy luận nhiều bước, xử lý ngữ cảnh dài, hoặc tránh hallucination.
-
Thêm các bước: lọc trước khi truy xuất, hybrid index, rerank, viết lại câu hỏi, lưu trữ memory, dự đoán sau truy xuất.
-
Từ “truy xuất tĩnh” sang pipeline mô-đun:
Retrieve → Read → Predict/Rewrite → Retrieve → Rerank → Read
-
Hữu ích khi cần độ chính xác, khả năng xử lý ngữ cảnh, và truy vết nguồn.
-
Kết nối hoặc tạo Knowledge Graph, ghép cùng Vector DB.
-
Prompt được bổ sung đường dẫn graph & metadata node → cho phép suy luận có giải thích.
-
Dùng nhiều trong tìm kiếm doanh nghiệp, y tế, tài chính – nơi logic cấu trúc rất quan trọng.
-
Mô hình không chỉ “truy xuất” mà còn lập kế hoạch, hành động và điều phối.
-
Quyết định:
-
Truy xuất gì
-
Gọi function/tool nào
-
Lưu kết quả ra sao
-
Kết hợp prompt + dữ liệu truy xuất + schema tool để gọi API hoặc hành động bên ngoài.
-
Stack gồm: function tool, graph DB, relational memory, agent logic.
-
Là xu hướng cho AI Agent, copilots và trợ lý sản xuất quy mô lớn.
No Comments